Under the banner of #NormaalAcademischPeil ('normal academic standard'), Dutch universities have started a coalition to demand a structural increase of €1.1 billion in government funding. This action is broadly supported by the academic community, and I'm also sympathetic to it myself. However, I feel that the action is too narrowly aimed at defending the interests of universities, without properly considering the role of universities in society at large.
The problems at Dutch universities are very real and multifaceted; they touch upon things such as the pervasiveness of temporary contracts, hypercompetion for grant funding, and the high salaries of full professors.
However, the coalition has chosen to focus on the figure below as illustrating The Problem. And it's this figure that I will also focus on in this post, because I believe that it reflects a complex reality that is very different from the simplified picture painted by the coalition.
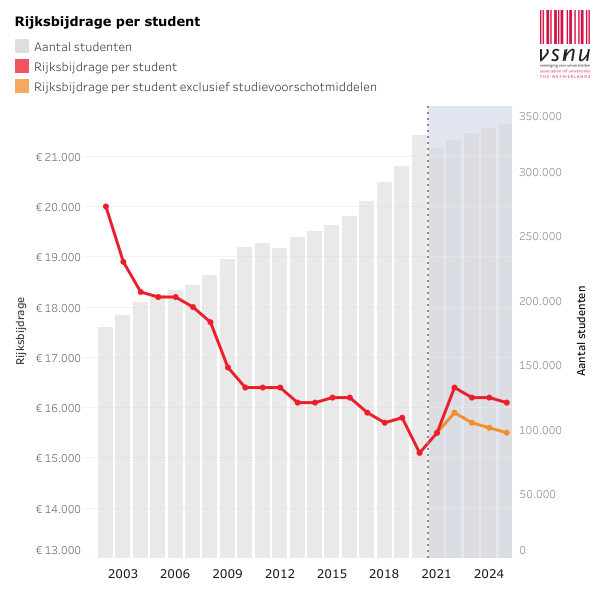
'The Problem' is that the number of students who attend a Dutch university has almost doubled over the past twenty years (the grey bars; from about 175,000 to 300,000). In that same period, government funding per student has decreased by 25% (the red line; from about €20k per student to about €15k). In other words, universities have more budget in total, but less budget per student.
Based on this, the coalition correctly points out that the quality of university education has suffered. In practice, this means that many lectures have become mass productions. (I have lectured for a …